Duplicate content has always been an issue for content creators, marketers, and businesses. If you are optimizing content for SEO, it is essential to know what is considered duplicate content by Google and what isn’t duplicate content. There are, unfortunately, a lot of myths related to duplicate content, Google penalties, and search engine ranking that needs to be debunked.
Let’s take a deep dive and decode everything related to duplicate content, what’s considered duplicate by Google, and how it is related to SEO.
What is Duplicate Content?
Any content that is found on the internet in more than one place is known as duplicate content. This could be on the same domain or different domains. So, any piece of content that is found at more than one URL is known as duplicate content.
Here is an example of duplicate content on a single domain:

This is a type of duplicate content on the same domain.
Another example of duplicate content is content syndication. Here is an article that’s published on AllBusiness:
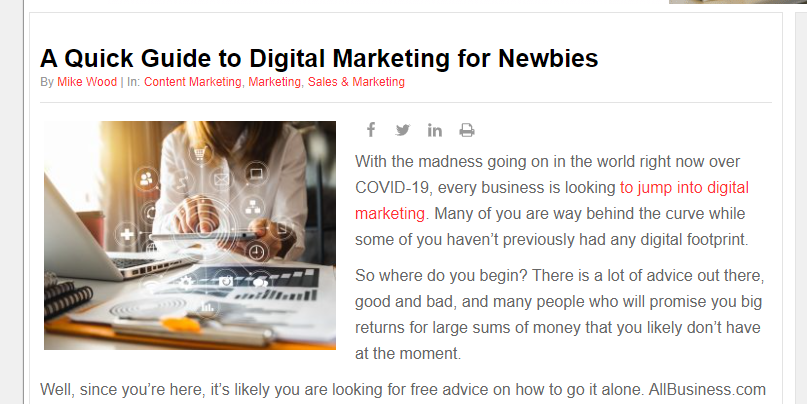
Here is the same article syndicated on Forbes:
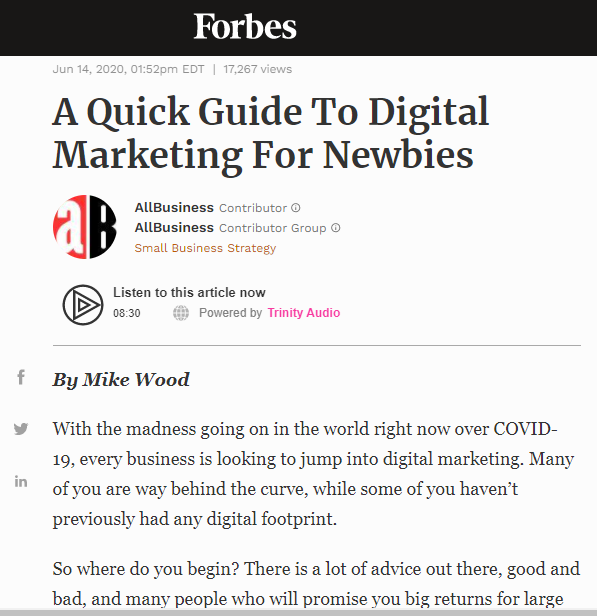
So, having duplicate content isn’t a big deal. Even if you don’t syndicate content, people can republish your article or content without your permission (with or without a link back). You can’t stop people from sharing and republishing your content or its excerpts (known as content scraping) unless you have a dedicated duplicate content finder team.
Here is an example of scraped content:
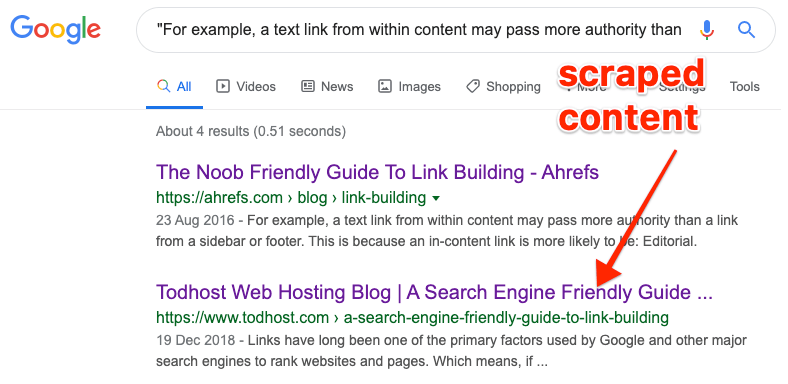
But is it really an issue? Let’s find out.
What is Considered Duplicate Content by Google
So, what’s Google policy on duplicate content, what it considers duplicate content, and how it reacts to duplicate content?
Google has clearly mentioned here and as discussed here that Google doesn’t have a duplicate content penalty. So, the most important thing to consider is that duplicate content won’t lead to a penalty:
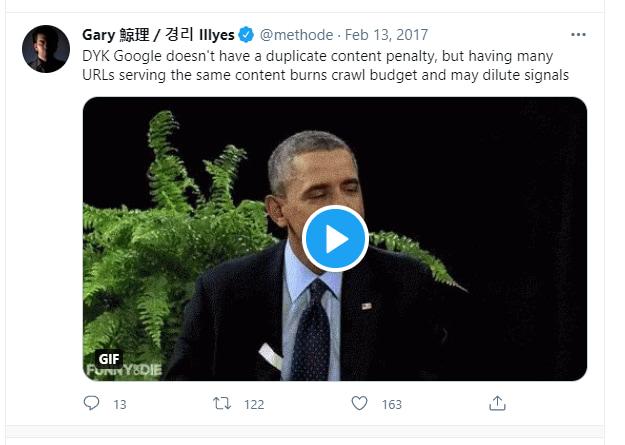
Here is how Google defines duplicate content:
Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar.
This isn’t problematic as Google admits that there are instances when content is duplicated (as discussed above). However, when content is deliberately duplicated with an intention to improve search engine rankings, it ruins the user experience.
But Google still won’t penalize your website even if you are involved in deceptive and manipulative practices.
One thing that Google strictly recommends is using a canonical URL that tells Google the preferred URL you want Google to show in search results. If you don’t use canonical URL, Google might show any page or content from the list of duplicate content. This means Google might show an article that you don’t want it to:
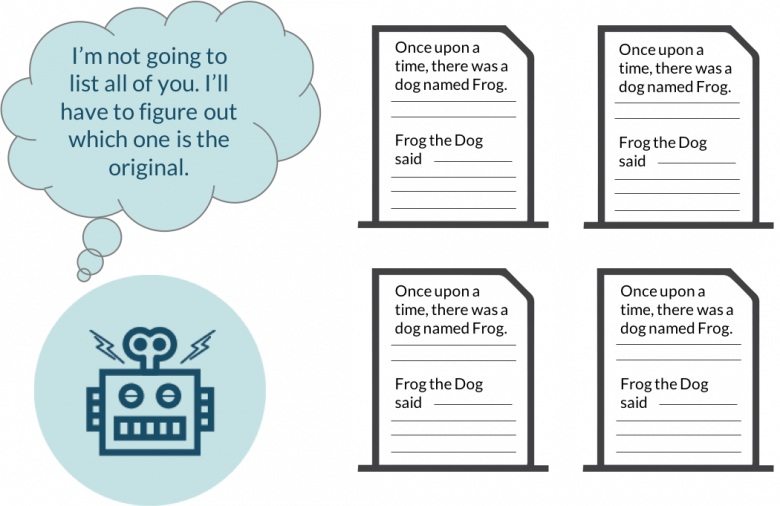
Canonical URL helps you set a preference so Google will show the original content.
Duplicate Content vs. Copied Content
Duplicate and copied content are the same. There isn’t any difference between the two, according to Google.
Copied content is the same while duplicate content isn’t always the exact copy of the original. It can be:
- Exact copy of original content
- Similar content with the same meaning.
Here is an example of duplicate content that isn’t copied:

This is content with a similar meaning but it isn’t copied content. However, Google will consider it as duplicate content and it will be treated as such.
Duplicate Content and SEO
Is duplicate content bad for SEO?
While Google doesn’t penalize your website for duplicate content, this doesn’t mean having duplicate content might not impact SEO.
It does.
There isn’t any direct impact on ranking. However, you might face a few SEO-related challenges due to duplicate content.
How Duplicate Content Impact SEO
Here are different ways duplicate content impact SEO:
- The most important one is that syndicated content outranks your original content. This means you’ll lose a certain portion of website traffic. For example, if you republish your blog post on Medium and your Medium post outranks the blog post on your website.
- You’ll have unfriendly URLs that might not look good on the search results page. Readable URLs are appreciated by users and if a URL doesn’t make sense, it will receive fewer clicks. So, search engines will be OK with the URL, your target audience might not be OK. A reduction in CTR will impact ranking as both are positively correlated.
- If your content is republished and syndicated on several websites and blogs, Google will not always include all the versions in search. It shows the best version that it thinks is most relevant and it might not be your website. This means your original content might not show at all in search results. And there isn’t anything you can do about it.
- Having duplicate content on your domain means having multiple URLs with the same content. This isn’t good for backlinks as all the URLs will attract backlinks naturally. Your links will be distributed among different URLs that will have less impact as opposed to if all the backlinks point to a single page.
- Duplicate content on your domain impacts crawl speed and frequency. If you have a lot of duplicate pages across your domain, crawlers will need a lot of time to crawl and recrawl these pages. This exhausts the crawl budget and your website might not be crawled too frequently leading to a delay in indexing of new content.
Conclusion
Duplicate content might get you penalized and it doesn’t impact SEO directly. But it doesn’t mean you should get casual about it. You need to avoid duplicate content on your domain. Make sure there is only one URL for each page/content.
As far as content syndication and scraping are concerned, you don’t have full control over both. People will republish your content with or without a backlink. As long as you are getting credit for your content, it is OK. You can also request Google to remove such pages from search results that are duplicating your content and aren’t taking it down despite requests.
What is considered duplicate content by Google isn’t important. What you consider duplicate content and what actions you take to control it are important questions to address.
Featured Image: Pexels